Median of Medians Algorithm
Quickselect is linear-time on average, but it can require quadratic
time with poor pivot choices. This is because quickselect is a
decrease and conquer algorithm, with each step taking O(
n)
time in the size of the remaining search set. If the search set
decreases exponentially quickly in size (by a fixed proportion), this
yields a
geometric series times the O(
n)
factor of a single step, and thus linear overall time. However, if the
search set decreases slowly in size, such as linearly (by a fixed number
of elements, in the worst case only reducing by one element each time),
then a linear sum of linear steps yields quadratic overall time. For example, the worst case occurs when pivoting
on the smallest element at each step, such as applying quickselect for
the maximum element to already sorted data and taking the first element
as pivot each time.
If one instead consistently chooses "good" pivots, this is avoided
and one always gets linear performance even in the worst case. A "good"
pivot is one for which we can establish that a constant proportion of
elements fall both below and above it, as then the search set decreases
at least by a constant proportion at each step, hence exponentially
quickly, and the overall time remains linear. The median is a good pivot
– the best for sorting, and the best overall choice for selection –
decreasing the search set by half at each step. Thus if one can compute
the median in linear time, this only adds linear time to each step, and
thus the overall complexity of the algorithm remains linear.
The median-of-medians algorithm does not actually compute the exact
median, but computes an approximate median, namely a point that is
guaranteed to be between the 30th and 70th percentiles .
Thus the search set decreases by a fixed proportion at each step,
namely at least 30% (so at most 70% left). Lastly, the overhead of
computing the pivot consists of recursing in a set of size 20% the size
of the original search set, plus a linear factor, so at linear cost at
each step, the problem is reduced to 90% (20% and 70%) the original
size, which is a fixed proportion smaller, and thus by induction the
overall complexity is linear in size.
Median-of-medians algorithm:
- Line up elements in groups of five (this number 5 is not important,
it could be e.g. 7 without changing the algorithm much). Call each group
S[i], with i ranging from 1 to n/5.
- Find the median of each group. (Call this x[i]). This takes 6
comparisons per group, so 6n/5 total (it is linear time because we are
taking medians of very small subsets).
- Find the median of the x[i], using a recursive call to the
algorithm. If we write a recurrence in which T(n) is the time to run the
algorithm on a list of n items, this step takes time T(n/5). Let M be
this median of medians.
- Use M to partition the input and call the algorithm recursively on one of the partitions, just like in quickselect.
The chosen pivot is both less than and greater than half of the elements in the list of medians, which is around
n/10 elements (½×
n/5)
for each half. Each of these elements is a median of 5, making it less
than 2 other elements and greater than 2 other elements outside the
block. Hence, the pivot is less than 3(
n/10) elements outside the block, and greater than another 3(
n/10)
elements inside the block. Thus the chosen median splits the elements
somewhere between 30%/70% and 70%/30%, which assures worst-case linear
behavior of the algorithm. To visualize:
One iteration on the list {0,1,2,3,...99}
|
12 |
|
15 |
|
11 |
|
2 |
|
9 |
|
5 |
|
0 |
|
7 |
|
3 |
|
21 |
|
44 |
|
40 |
|
1 |
|
18 |
|
20 |
|
32 |
|
19 |
|
35 |
|
37 |
|
39 |
|
13 |
|
16 |
|
14 |
|
8 |
|
10 |
|
26 |
|
6 |
|
33 |
|
4 |
|
27 |
|
49 |
|
46 |
|
52 |
|
25 |
|
51 |
|
34 |
|
43 |
|
56 |
|
72 |
|
79 |
| Medians |
17 |
|
23 |
|
24 |
|
28 |
|
29 |
|
30 |
|
31 |
|
36 |
|
42 |
|
47 |
|
50 |
|
55 |
|
58 |
|
60 |
|
63 |
|
65 |
|
66 |
|
67 |
|
81 |
|
83 |
|
22 |
|
45 |
|
38 |
|
53 |
|
61 |
|
41 |
|
62 |
|
82 |
|
54 |
|
48 |
|
59 |
|
57 |
|
71 |
|
78 |
|
64 |
|
80 |
|
70 |
|
76 |
|
85 |
|
87 |
|
96 |
|
95 |
|
94 |
|
86 |
|
89 |
|
69 |
|
68 |
|
97 |
|
73 |
|
92 |
|
74 |
|
88 |
|
99 |
|
84 |
|
75 |
|
90 |
|
77 |
|
93 |
|
98 |
|
91 |
(red = "(one of the two possible) median of medians", gray = "number < red", white = "number > red")
Proof of O(n) running time
The median-calculating recursive call does not exceed worst-case
linear behavior because the list of medians is 20% of the size of the
list, while the other recursive call recurses on at most 70% of the
list, making the running time

The O(
n) term
c n is for the partitioning work (we
visited each element a constant number of times, in order to form them
into n/5 groups and take each median in O(1) time).
From this, using induction – or summing the geometric series, obtaining
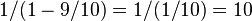
for overall scaling factor – one can easily show that
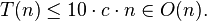
Code
// selects the median of medians in an array
int select(int *a, int s, int e, int k){
// if the partition length is less than or equal to 5
// we can sort and find the kth element of it
// this way we can find the median of n/5 partitions
if(e-s+1 <= 5){
sort(a+s, a+e);
return s+k-1;
}
// if array is bigger
// we partition the array in subarrays of size 5
// no. of partitions = n/5 = (e+1)/5
// iterate through each partition
// and recursively calculate the median of all of them
// and keep putting the medians in the starting of the array
for(int i=0; i<(e+1)/5; i++){
int left = 5*i;
int right = left + 4;
if(right > e) right = e;
int median = select(a, 5*i, 5*i+4, 3);
swap(a[median], a[i]);
}
// now we have array
// a[0] = median of 1st 5 sized partition
// a[1] = median of 2nd 5 sized partition
// and so on till n/5
// to find out the median of these n/5 medians
// we need to select the n/10th element of this set (i.e. middle of it)
return select(a, 0, (e+1)/5, (e+1)/10);
}
int main(){
int a[] = {6,7,8,1,2,3,4,5,9,10};
int n = 10;
int mom = select(a, 0, n-1, n/2);
cout<<"Median of Medians: " << a[mom] << endl;
return 0;
}